来源:晶报网 2022-12-26 15:20:31
2022年12月,在拉斯维加斯举办的2022亚马逊云科技re:Invent全球大会完美落幕,这一标志性的技术盛宴再一次给人们留下了无限的想象空间,等待大家在新的一年去持续探索和发掘。
而最让人关注的,应该就是各类新服务了,今年无论是Adam还是Swami博士的Keynote很多篇幅都是和数据相关的新服务和新特性,尤其是Swami博士关于数据创新起源的表述以及新的端到端云原生数据战略。所以,接下来将目光切回今天这篇文章关注的对象——数据,更具体地说是众多新发布中占据高位的Amazon Redshift云数据仓库。
简化数据摄入工作
最好是没有
要想数据分析到位,首先要保证有稳定、可靠的数据摄入通道,来实现端到端的第一环(其实还有第零环,是业务在数据源侧的规划),而这一块也是大部分数据工程中遇到最头疼的问题之一。首先,数据源就包含很多种,最常见的数据源包括关系型数据库、数据湖和实时的流数据。其次,不管是手动还是自动的ETL流水线,都需要专业的数据工程团队来构建和维护,并且经常要处理或介入数据结构的变更等情况。这次,Redshift连发多个功能特性来帮助客户解决或者消除这类问题。
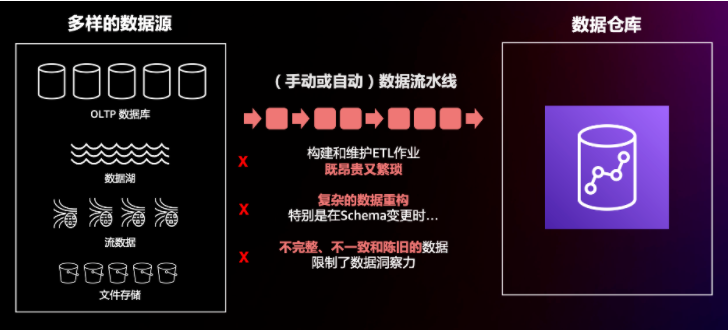
首先是最常见的关系型数据库,也就是经典的OLTP向OLAP的数据传递。如果是为了更快或者更实时地获取线上业务的事务数据来做分析,通常可以通过开启数据库的binlog来捕捉CDC变更,然后再使用解析CDC的工具如Amazon DMS、Debezium等来实现,这些都需要客户进行不断的监控、配置和优化。此外,不同的数据库和数据表可能会有不同的需求,这样就再加倍了数量级的维护成本。
相信大家对Redshift印象最深的一个功能就是Zero ETL,帮助客户完成从1到0的过程!Redshift通过与Amazon Aurora数据库深度集成,在事务型数据写入Aurora后,数据在底层被持续地复制到Redshift,完成行式数据存储到列式数据存储的转换,彻底消除了自己构建和维护复杂数据管道的工作。没有Hybrid OLTP和OLAP,仍然是熟悉的Amazon Purpose-Build(Aurora还是 Aurora,Redshift还是Redshift)各司其职解决最实际的问题。同时,客户的应用程序架构保持不变,读写端点指向Aurora,分析端点指向Redshift,但是底层已经不再是一大串接一大串的数据抽取、转换和加载,直接无缝衔接并且达到近实时的效果。
然后是数据湖S3,Redshift开始支持从S3数据湖中自动复制,手动挡升级自动挡。之前,如果想要拷贝数据都需要手动或者定时执行COPY命令,现在Redshift新添加了COPY JOB命令自动检测指定路径的新文件,跳过已经加载完毕的旧文件。以前编写的定时任务脚本可以退役了,而且再也不用担心手抖重复执行,生活变得更美好了。
如果业务需求是实时的,那么通过S3作为Staging存储再COPY的方式就跟不上节奏了,所以,流数据也要拿下。re:Invent之前,Redshift流式摄入已经开始支持Amazon Kinesis Data Streams,这次发布更是添加了Amazon Managed Streaming for Apache Kafka(MSK),同时流式摄入也正式推出,告别预览。从上面的图中可以看出,流式摄入合并了数据消费的过程,直接在Redshift中实现并持续加载到数据仓库。在Redshift中,流式摄入是通过物化视图的方式实现的(查找官方文档是在物化视图章节),用户还可以在这个物化视图基础上再配合其他数据叠加物化视图提高查询效率。另外,别忘了还可以给流式摄入开启自动刷新功能。从此,客户可以更简单地完成实时数据分析,包括IoT物联网设备、点击流、应用程序监控、欺诈检测和游戏实时排行榜等。
以上,Redshift简化了各种最经典的数据源ETL方式,数据坐等分析。
更多数据分析的利器
来点火花
数据已经妥妥地进到了数据仓库的碗里来,接下来就请开始它的表演了。此时,数据工程师表示Redshift SQL很好,但是还有些更复杂业务数据逻辑更适合通过代码的方式进行操作和处理(而不是通过UDF)。开源大数据生态体系下有非常丰富的软件供组织采用了,其中功能完善、发展稳定的Apache Spark往往是一个优先的选择。在亚马逊云科技平台上使用Spark并不复杂,有托管服务EMR和Glue保驾护航,还有新发布的Amazon Athena for Apache Spark可以极速启动交互。但是,说到Spark和Redshift之间进行数据分析还是需要折腾一下的,或者是通过将Redshift中的数据导出到S3中,或者是使用各种第三方的Spark连接器,前者需要多走一步浪费时间和资源,后者没有多少人维护不说,性能和安全性都令人堪忧。因此,Amazon Redshift integration for Apache Spark应运而生。

这个内置集成模式基于一个之前的开源项目,提升了性能和安全性,相信后续亚马逊云科技仍将继续跟进这个开源项目,并将各种升级改造的好东西贡献给社区。目前,EMR、EMR on EKS、EMR Serverless和Glue(限定版本)都预置了打包好的连接器和JDBC驱动程序,客户完全可以直接开始编写代码(有爱好者迫不及待连夜在EMR Studio中使用EMR on EKS完成了对Redshift Serverless和集群模式的交互式读写测试,体验极佳),对Redshift中的数据进行处理。如果客户的数据分析工作负载以Spark为主,也可以通过Spark统一对各种数据源的分析。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。